F1-Score
In the realm of machine learning and data science, evaluating the performance of predictive models is paramount. One common metric used for this purpose is the F1-score. The F1-score is particularly useful when dealing with imbalanced datasets or when both precision and recall are of equal importance. In this article, we will delve deep into the intricacies of the F1-score, understanding its calculation, significance, and practical applications.
What is F1-Score?
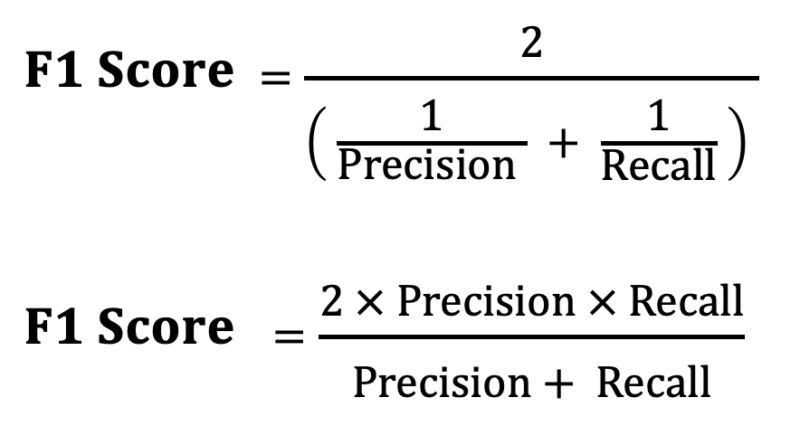
The F1-score is a statistical measure of a model’s accuracy, taking into account both precision and recall. It is the harmonic mean of precision and recall and provides a single score that represents the balance between the two. The formula for calculating the F1-score is:
�1=2������������������������+������
Where:
- Precision is the number of true positive predictions divided by the total number of positive predictions (true positives and false positives).
- Recall is the number of true positive predictions divided by the total number of actual positive instances (true positives and false negatives).
Understanding Precision and Recall
Before diving into the F1-score, it’s crucial to understand precision and recall individually.
Precision: Precision measures the accuracy of positive predictions made by the model. It answers the question: “Of all the instances predicted as positive, how many are actually positive?” A high precision indicates that the model is making fewer false positive predictions.
���������=��������������������������+��������������
Recall: Recall, also known as sensitivity or true positive rate, measures the ability of the model to identify all relevant instances. It answers the question: “Of all the actual positive instances, how many did the model correctly predict as positive?” A high recall indicates that the model is capturing most of the positive instances.
������=��������������������������+��������������
Interpreting F1-Score
The F1-score combines precision and recall into a single metric, providing a balanced assessment of a model’s performance. It is particularly useful in scenarios where there is an imbalance between the classes or when both precision and recall are equally important.
- F1-score ranges from 0 to 1, where 1 indicates perfect precision and recall, and 0 indicates poor performance.
- A higher F1-score implies better model performance in terms of both precision and recall.
- F1-score reaches its maximum value when precision and recall are balanced.
Applications of F1-Score
The F1-score finds applications in various domains, including:
- Binary Classification: In binary classification problems, where there are only two classes (positive and negative), the F1-score provides a comprehensive evaluation of the model’s performance.
- Information Retrieval: In information retrieval tasks such as document retrieval or search engines, F1-score helps in measuring the effectiveness of the system in returning relevant documents.
- Medical Diagnosis: In medical diagnosis, especially in detecting diseases where false positives or false negatives can have serious consequences, F1-score aids in evaluating the performance of diagnostic models.
- Anomaly Detection: F1-score is valuable in anomaly detection tasks where identifying rare events is crucial, and both precision and recall play significant roles.
Challenges and Considerations
While F1-score is a useful metric, it’s essential to consider its limitations and challenges:
- Threshold Dependency: F1-score is sensitive to the threshold used for classifying instances as positive or negative. A change in the threshold can affect precision, recall, and consequently, the F1-score.
- Imbalanced Datasets: In datasets where one class significantly outnumbers the other, F1-score might not accurately reflect the model’s performance, especially if one of the classes is of more interest.
- Domain Specificity: The interpretation of F1-score can vary based on the domain and the specific objectives of the task. What constitutes acceptable performance might differ from one application to another.
Conclusion
The F1-score is a valuable metric for evaluating the performance of classification models, providing a balanced assessment of precision and recall. By considering both false positives and false negatives, F1-score offers insights into a model’s effectiveness, particularly in scenarios with imbalanced datasets or when both precision and recall are equally important. Understanding the nuances of F1-score empowers data scientists and machine learning practitioners to make informed decisions about model performance and optimization strategies.